

Régulièrement confronté aux problématiques d’indexation incomplète sur des boutiques en ligne, j’ai décidé de réaliser un petit bookmark des intervention fréquentes à réaliser lors de la prise en main en portefeuille d’un site e-commerce basé sur le CMS Prestashop.
Je prends soin d’éviter les étapes liées à l’optimisation sémantique : balisage et métadonnées, pour me consacrer dans cet article aux préconisations fréquentes qui reviennent lors d’une analyse des logs serveur d’un e-commerçant.
Déterminer l’offre d’url utiles : url potentiel commercial
Pour évaluer l’ampleur de la tâche à accomplir, rien ne vaut un petit crawl du set d’url présentes sur le Prestashop. J’entends là, les url utiles, c’est-à-dire celles qui doivent générer du trafic direct en provenance des moteurs de recherche. Pour cela rien de plus simple, vous connaissez déjà la formule : votre scraper préféré Xenu ou Screaming Frog.
J’ai une préférence pour Screaming Frog qui permet depuis peu d’associer les données Analytics (que nous utiliserons plus tard).
Prenez soin de respecter les consignes du fichier robots.txt, vous allez voir, cela a toute son importance
Objectif à atteindre : 100% des url du site crawlées au moins une fois par mois
Récupérer les logs serveur : Googlebot de préférence
Sujet tendance ces derniers mois, l’analyse des logs serveur et plus particulièrement des logs Googlebot constitue le niveau d’analyse le plus proche entre votre site internet et l’activité des moteurs de recherche. Plusieurs possibilités :
Récupérer vous même les logs directement sur votre serveur (contrairement à ce que j’entends souvent, il est tout à fait possible d’extraire les logs sur un serveur mutualisé). De manière automatique, ou pas, pour une analyse constituant l’entrée en matière, pas besoin de mettre en place une machine à gaz.
Récupérer les logs avec une interface graphique : pour ceux qui souhaitent consulter régulièrement les logs avec de nombreuses statistiques relatives au SEO, quelques solutions existent, souvent payantes, et d’autres arrivent prochainement du côté de Spiderlog. Je retiens pour ma part la solution gratuite de Jean Benoît > http://box.watussi.fr. Un analyseur de logs gratuit qui fait bien le boulot pour le peu de configuration qu’il demande. J’en profite pour ceux qui ne sont pas à l’aise avec les logs, que Jean Benoît organise régulièrement des ateliers et formations sur l’analyse de logs. Pour les bordelais, une session est prévue sur Bordeaux le 6 novembre, ça peut être l’occasion de s’y mettre, surtout si vous manipulez des sites à fort volume de pages.
Une fois les logs récupérés, on exporte cela au format de son choix pour débuter les analyses et les préconisations.
Analyse rapide des logs Googlebot
Quelle période analyser ?
En théorie j’aime bien partir sur 60 jours, mais parfois, point besoin de remonter si loin, surtout pour une première analyse consistant à éliminer les premiers facteurs bloquants. On va donc se concentrer sur le nettoyage des url inutiles, souvent fréquentes sur Prestashop.
Il n’est d’ailleurs pas rare d’avoir près de 80% des hits Googlebots concentrés sur des pages inutiles de votre site. Nous en reparlerons.
Je le rappelle l’idée n’est pas ici de détailler comment on analyse des logs mais plutôt d’être efficient dans la mise en place des premières préconisations, qui vous permettront de travailler sur une base plus saine par la suite.
Tableau croisé dynamique et Excel
On importe et nettoie ses données pour les rendre utilisables dans Excel. Pour cela rien de plus simple, il suffit de convertir ses données et de donner un intitulé à chaque colonne.
Voici un exemple de champs. J’aime attribuer un id unique à chaque ligne de logs pour faciliter la manipulation des données et notamment la visualisation des hits/url.
On détermine le taux de crawl global

On calcule la fréquence de crawl journalière
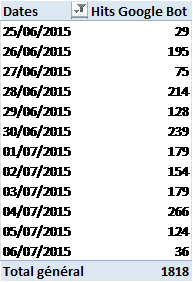
Toujours avec le même tableau croisé dynamique, on doit être capable de sortir toutes ses données en quelques clics.
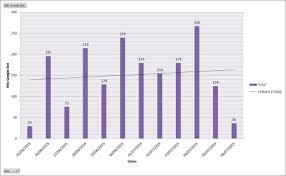
Si un graphique ne vous parle pas, un simple tableau sur lequel vous ajoutez des mises en forme conditionnelles suffira.
Déséquilibres de crédit crawl sur les pages du site
Pour mieux comprendre les amplitudes et irrégularités de la fréquence de crawl, il est nécessaire d’examiner en détail la fréquence de crawl par URL.
On découpe alors la fréquence globale de crawl en 2 métriques : nombre de crawls URL et part du crawl global.
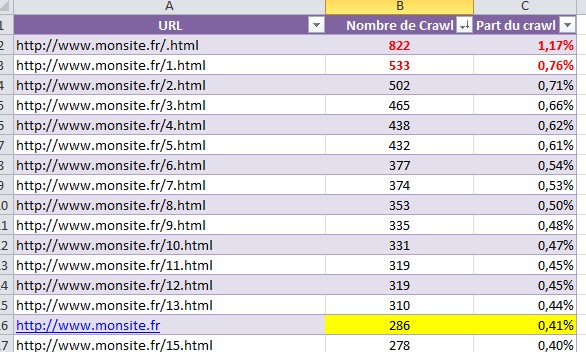
On relève les pages en erreur qui ne justifient pas le crawl et on détermine l’action à mener. Suppression et/ou redirection.
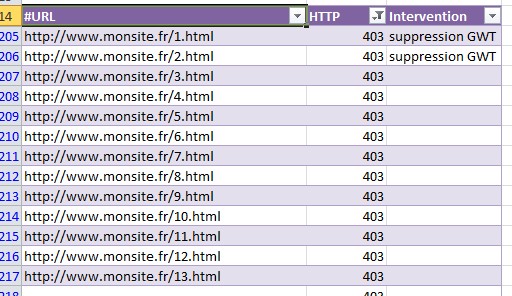
On relève les pages non crawlées sur la période, et c’est ici qu’un crawl des url utiles est indispensable. Pour faire cela, rien de plus simple, il suffit de mettre en place la fonction rechercheV sur Excel pour faire coïncider le set d’url utiles déterminé par Screaming Frog ou autre et les url crawlées collectées sur le fichier de logs serveur.
Volume de crawl par niveau de profondeur
Le PageRank et le maillage interne ayant une incidence importante sur l’action de crawl, on doit constater une baisse de la fréquence de crawl à mesure que le niveau de profondeur des pages augmente. Toujours avec le fichier Screaming, on fait coïncider la profondeur des pages avec les hits retournés par le fichier de logs serveur.
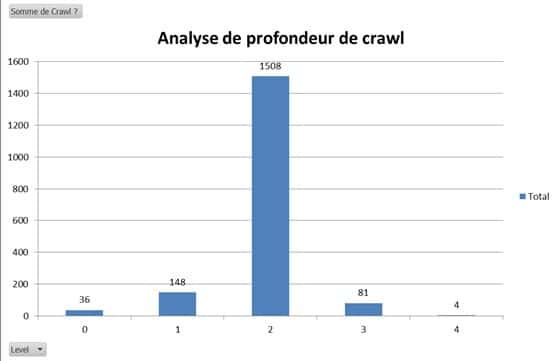
Pages non crawlées
Une page non crawlée ou faiblement crawlée donne lieu à une indexation et des performances de classement réduites.
Méthode Screaming Frog > recherchev sur le fichier des logs.
Crawl et performances commerciales
Petit bonus : avec la nouvelle mise à jour de Screaming Frog, il est possible de collecter les données de l’api Analytics avec le crawl du site. On peut ainsi imaginer réaliser des statistiques d’audience en provenance du trafic organique en fonction des fréquences de crawl sur une url. On peut par ailleurs y associer le CA. Associer les performances commerciales peut notamment permettre de dégager les différents niveaux de priorité pour la mise en place des préconisations.
NB : L’audience des URL ne dépend pas seulement du classement et des positions des URL dans les résultats de recherche. Sont à prendre en considération les volumes de recherche sur les expressions, l’offre produits, le positionnement du client et les champs lexicaux positionnés.
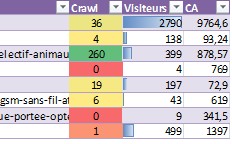
Déterminer les facteurs bloquants au crawl
Comme nous avons pu le constater sur les différentes analyses, de nombreuses pages peuvent ne pas être correctement crawlées (voir pas du tout), et ce malgré une architecture du site correcte !
Il est donc indispensable de passer un à un les différents facteurs bloquants du crawl pour isoler les points de blocages et rendre accessibles les URL constituant l’offre commerciale.

Duplication de contenus et Prestashop
La première partie étant très générique intéressons nous maintenant aux spécificités de Prestashop. Principal point faible commun à de nombreux CMS : la duplication de contenus. Interne ou externe elle s’affirme de plus en plus comme le véritable frein à l’indexation complète d’un site internet. Nous allons donc parcourir quelques exemples et problèmes fréquents sur Prestashop.
Pagination, filtres, pages inutiles…
Très pratiques pour l’utilisateur, beaucoup moins appréciées des moteurs, les url inutiles doivent être maîtrisées. Ce sont ces pages qui consomment le plus de crédit crawl lorsqu’elles ne font pas l’objet de consignes dans le robots.txt. Pour faire simple, on va appliquer un balise « rel Canonical ». Je vous invite à consulter l’excellent article sur Effi10 pour sa mise en place.
Désindexer les pages inutiles de Prestashop et bloquer l’accès aux robots
Une fois que l’on a déterminé les pages inutiles au crawl, on va appliquer la méthode de Jérôme (Noindex sur toutes les pages inutiles de Prestashop) pour demander la désindexation au robots. Puis une fois cette désindexation prise en compte, on va tout simplement leur interdire le crawl. On récupérera ainsi de précieux crédits crawl pour nos pages utiles.
Lorsque l’on souhaite interdire une page aux robots, je préfère toujours laisser le robot la désindexer avant d’en bloquer l’accès. Au risque de se retrouver avec un snippet du type : Accès bloqué par le fichier robots.txt du serveur.
Pour que le robot puisse prendre en compte la consigne de désindexation, vous devez lui permettre d’explorer la page !
Tips : en supprimant la page directement dans la Search Console de Google, vous pouvez ignorer cette étape MAIS cela implique que vous vous fichez des autres moteurs de recherche !
je découpe donc la procédure de Jérôme en 2 étapes, ce qui nécessite de modifier 2 fois le hook.
première passe : noindex follow
seconde passe : une fois la désindexation prise en compte : noindex, nofollow
Pour les autres pages qui ne doivent pas être explorées
Certaines autres pages peuvent paraître difficiles à manipuler à la volée à l’aide d’un simple Hook sur le fichier header du thème Prestashop. Pour cela, rien de plus simple, on se contentera d’enrichir le robots.txt en ayant pris soin de lister l’ensemble des pages à bloquer. Le fichier logs serveur, une fois traité, vous donnera l’ensemble des hits inutiles à interdire.
Utilisez les Wildcard pour établir des règles précises d’exploration
Il est possible de remplacer une séquence de caractères en utilisant un astérisque (*), elles sont nombreuses et vous permettent de vous sortir de toutes les situations. Source
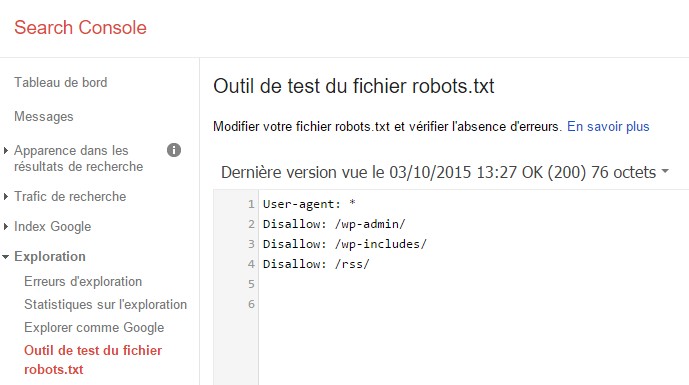
Utiliser la Search Console GWT de Google pour tester son robots.txt
Je vous invite à vous servir de l’utilitaire proposé par Google dans la Search Console pour tester vos consignes au sein de votre robots.txt. Surtout dans le cas de la mise en place de Wildcard, ceci, afin de ne pas vous retrouver avec des url inexplorées avec un snippet d’erreur d’exploration.
Vous l’aurez compris, ici il ne s’agissait que de la partie indexation du catalogue. Pour la suite et notamment la cohérence entre les url de catégorie et les url réécrites et le maillage interne il faudra revenir.
Si vous n’avez pas de contenus dupliqués on et off site, vous devriez en respectant les règles de base que vous trouverez partout sur la toile, obtenir un taux d’indexation du catalogue proche de 100%
Vous avez aimé cet article ? Alors partagez-le avec vos amis en cliquant sur les boutons ci-dessous :


« seconde passe : une fois la désindexation prise en compte : noindex, nofollow »
Qu’est-ce qui justifie selon toi le paramètre nofollow dans la seconde passe ?
Je ne comprends pas le sens de ta question.
Si c’est pour savoir pourquoi je ne le fais pas à la première passe > les robots doivent pouvoir crawler la page pour prendre en compte la meta noindex.
Si c’est pour sa voir pourquoi je ne me contente pas d’utiliser le robots.txt, c’est juste une double précaution pour avoir la garantie que mes instructions seront bien prises en compte.
Désolé, ni l’une ni l’autre des propositions ne répondent à ma question. Je vais essayer de la formuler autrement. Pourquoi ne pas te contenter d’un « noindex », et ainsi, au cas où un bot passe sur la page, il peut continuer son chemin, non (en utilisant nofollow, tu crées une dangling page) ?
C’est un risque à prendre, mais si tu maîtrises bien ton maillage (non abordé ici) tu n’as rien à craindre.
Si tu ne places pas de nofollow sur tes filtres par exemple ou ta pagination, les robots risquent de consommer 70% de ton crédit crawl sur des pages que tu ne souhaites pourtant pas indexer, et qui n’apporteront jamais un visiteur en provenance des résultats de recherche.
Sur les pages référentes des pages inutiles, je préfère rendre inaccessibles (via un chargement asynchrone, ou un brouillage JS) les liens qui désignent ces dernières, et pour éviter l’indexation, une meta noindex. Pas de dépense de crawl non plus, en faisant ça. L’avantage, par rapport à la méthode qui vise à créer des dangling pages, c’est que si un bot pointe le bout de son nez, il va poursuivre son chemin sur les contenus utile du site ; il ne va pas se retrouver dans une impasse. Je me permets d’ajouter un petit mot sur l’utilisation de rel canonical, qui est loin d’être idéale du point de vue de l’optimisation du crawl, vs un brouillage de lien, par exemple, puisque le bot devra crawler la page inutile pour prendre connaissance de la directive. Avec un lien brouillé, il n’aura d’autre choix que de s’orienter vers une page utile. 🙂 De l’extérieur du site, le bot viendra, certes, sur la page inutile, mais il continuera son chemin vers les pages utiles. Pas de problème non plus pour faire circuler le PageRank ; quand la dangling page empêchera, au contraire, toute circulation du PR. 🙁 En conséquence, la méthode dont tu parles, tout en étant plutôt simple à mettre en place, limite considérablement la casse (nombre de hits Googlebot sur les pages inutiles), et c’est évidemment une très bonne chose. Toutefois, ce n’est pas celle que je préconiserais, car si elle empêche une évidente dépense de crawl, elle comporte les inconvénients relatifs à la présence de dangling pages dans la structure d’un site.
Je trouve çà hyper intéressant la partie crawl et indexation surtout pour les navigations à facette. Les 2 avis se défendent, effectivement créer des dandling pages on a toujours appris que c’était pas bien. Mais à certains moments je pense qu’il faut faire confiance au bon sens. Mon bon sens me dit que demander à Google de crawler des pages inutiles c’est lui faire dépenser son électricité inutilement et c’est le poste de dépense le plus important de google il me semble. En plus, même si aujourd’hui j’applique encore le noindex, follow pour le faire circuler, j’aimerai que le bot se concentre encore plus sur les pages les plus importantes. L’idéal effectivement c’est une navigation à facette où seule les liens vers les facettes utiles sont viisbiles par google. Certains e-commercant vont ca très bien d’ailleurs. Mais cela demande des bons dev derrière et pour un petit e-commercant c’est pas toujours simple.
Après je serais curieux de savoir si tu as des stats de crawl Loïc avec cette technique plutot qu’avec noindex, follow histoire de comparer.
Tu as très bien résumé la philosophie de l’article en une seule phrase : « Mais cela demande des bons dev derrière et pour un petit e-commercant c’est pas toujours simple ».
L’idée de départ est bien de faire indexer 100% du catalogue. Cette méthode le permet. Après, on peut dialoguer sur les optimisations à faire, mais on sort de l’idée simpliste qui est de résoudre un problème fréquent : mon site tourne sur 3 pattes avec seulement 45% de ses produits d’indexés ! Je ne parle même pas de positions à ce stade !
Pas de stats sur les 2 méthodes, mais raisonnement basé sur l’expérience des 2 méthodologies.